












|
Reputation models |
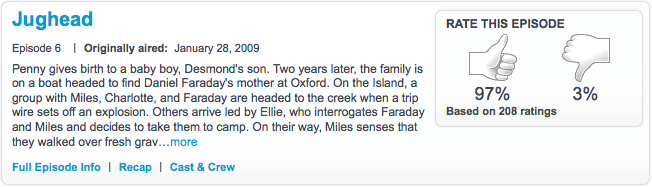
Vote-to-promote, favorites, flagging, simple ratings, and so on |
|
Inputs |
Scalar |
|
Processes |
Counters, accumulators |
|
Common uses |
Site personalization and display Input to predictive modeling Personalized search ranking component |
|
Pros |
A single click is as low-effort as user-generated content gets. Computation is trivial and speedy. Intended for personalization, these inputs can also be used to generate aggregated community ratings to facilitate nonpersonalized discovery of content. |
|
Cons |
It takes quite a few user inputs before personalization starts working properly, and until then the user experience can be unsatisfactory. (One method of bootstrapping is to create templates of typical user profiles and ask the user to select one to autopopulate a short list of targeted popular objects to rate quickly.) Data storage can be problematic-potentially keeping a score for every target and category per user is very powerful but also very data intensive. |

|
Reputation models |
Vote-to-promote, favorites, flagging, simple ratings, and so on |
|
Inputs |
Quantitative-normalized, scalar |
|
Processes |
Counters, averages, and ratios |
|
Common uses |
Aggregated rating display Search ranking component Quality ranking for moderation |
|
Pros |
A single click is as low-effort as user-generated content gets. Computation is trivial and speedy. |
|
Cons |
Too many targets can cause low liquidity. Low liquidity limits accuracy and value of the aggregate score. See Chap_3-Low_Liquidity_Effects . Danger exists of using the wrong scalar model. See Chap_3-Bias_Freshness_and_Decay . |
| Activity | Point Award | Maximum/Time |
|
First participation |
+10 |
+10 |
|
Log in |
+1 |
+1 per day |
|
Rate show |
+1 |
+15 per day |
|
Create avatar |
+5 |
+5 |
|
Add show or character to profile |
+1 |
+25 |
|
Add friend |
+1 |
+20 |
|
Be friended |
+1 |
+50 |
|
Give best answer |
+3 |
+3 per question |
|
Have a review voted helpful |
+1 |
+5 per review |
|
Upload a character image |
+3 |
+5 per show |
|
Upload a show image |
+5 |
+5 per show |
|
Add show description |
+3 |
+3 per show |
|
Reputation models |
Points |
|
Inputs |
Raw point value (this type of input is risky if disparate applications provide the input; out-of-range values can do significant social damage to your community) An action-type index value for a table lookup of points (this type of input is safer; the points table stays with the model, where it is easier to limit damage and track data trends) |
|
Processes |
(Weighted) accumulator |
|
Common uses |
Motivation for users to create content Ranking in leaderboards to engage the most active users Rewards for specific desirable actions Corporate use: identification of influencers or abusers for extended support or moderation In combination with quality karma in creating robust karma. (See Chap_4-Robust_Karma ) |
|
Pros |
Setup is easy. Incentive is easy for users to understand. Computation is trivial and speedy. Certain classes of users respond positively and voraciously to this type of incentive. See Chap_5-Egocentric_Incentives . |
|
Cons |
Getting the points-per-action formulation right is an ongoing process, while users continually look for the sweet spot of minimum level of effort for maximum point gain. The correct formulation takes into account the effort required as well as the value of the behavior. See Chap_5-Egocentric_Incentives . Points are a discouragement to many users with altruistic motivations. See Chap_5-Altruistic_Incentives and Chap_7-Leaderboards_Considered_Harmful . |
|
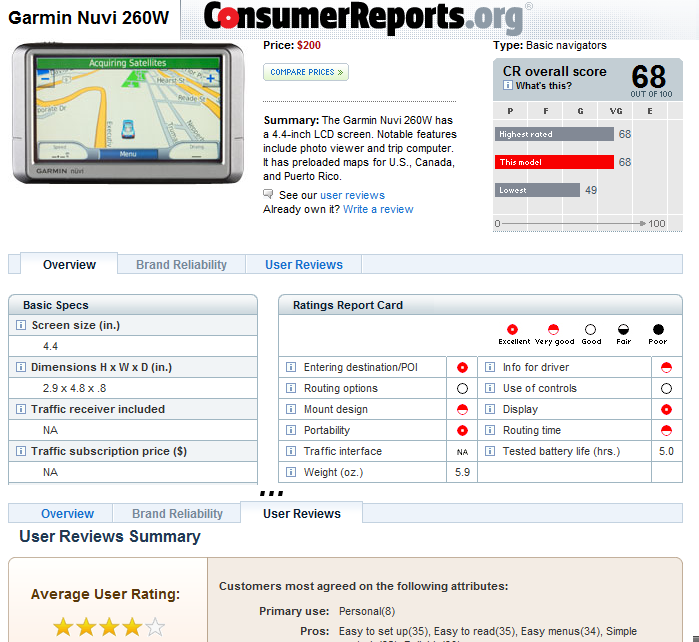
Reputation models |
Ratings-and-reviews, eBay merchant feedback, and so on |
|
Inputs |
All types from multiple sources and source types, as long as they all have the same target |
|
Processes |
All appropriate process types apply-every compound community claim is custom built |
|
Common uses |
User-created object reviews Editor-based roll-ups, such as movie reviews by media critics Side-by-side combinations of user, process, and editorial claims |
|
Pros |
This type of input is flexible; any number of claims can be kept together. This type of input provides easy global access; all the claims have the same target. If you know the target ID, you can get all reputations with a single call. Some standard formats for this type of input-for example, the ratings-and-reviews format-are well understood by users. |
|
Cons |
If a user is explicitly asked to create too many inputs, incentive can become a serious impediment to getting a critical mass of contributions on the site. Straying too far from familiar formatting, either for input or output, can create confusion and user fatigue. There is some tension between format familiarity and choosing the correct input scale. See Chap_6-Good_Inputs . |

|
Reputation models |
Models are always custom; inferred karma is known to be part of the models in the following applications:
|
|
Inputs |
Application external values; examples include the following: * User account longevity * IP address abuse score * Browser cookie activity counter or help-disabled flag * External trusted karma score |
|
Processes |
Custom mixer |
|
Common uses |
Partial karma substitute: separating the partially known from the complete strangers Help system display: giving unknown users extra navigation help Lockout of potentially abused features, such as content editing, until the user has demonstrated familiarity with the application and lack of hostility to it Deciding when to route new contributions to customer care for moderation |
|
Pros |
Allows for a significantly lower barrier for some user contributions than otherwise possible, for example, not requiring registration or login. Provides for corporate (internal use) karma: no user knows this score, and the site operator can change the application's calculation method freely as the situation evolves and new proxy reputations become available. Helps render your application impervious to accidental damage caused by drive-by users. |
|
Cons |
Inferred karma is, by construction, unreliable. For example, since people can share an IP address over time without knowing it or each other, including it in a reputation can undervalue an otherwise excellent user by accident. However, though it might be tempting for that reason to remove IP reputation from the model, IP address is the strongest indicator of bad users; such users don't usually go to the trouble of getting a new IP address whenever they want to attack your site. Inferred karma can be expensive to generate. How often do you want to update the supporting reputations, such as IP or cookie reputation? It would be too expensive to update them at very single HTTP roundtrip, so smart design is required. Inferred karma is weak. Don't trust it alone for any legally or socially significant actions. |